In this blog post, I will explore the emergent properties in foundational and fine-tuned AI models spanning Language, Video and Code models to discover more about AI models, what emergent properties are, how they occur and the implications of them in model usage.
Emergent properties are properties that occur in model inference (usage) that the model wasn’t explicitly trained to do but instead has picked up based on the training data it was provided. This leads to a lot of interesting model quirks like an AI model that generates video being able to mimic physics or a language model understanding data patterns and basic mathematics.
Overview of the AI
AI models, including those used for language processing like GPT, LLaMA, and Gemini, or video processing like Runway and Sora, are complex algorithms designed to emulate human-like abilities in processing and generating content. These models are part of a broader category of machine learning models, which learn from data to make predictions or decisions without being explicitly programmed to perform the task. it is this process of no explicit tasks being introduced which allows emergent properties to occur.
Overview of AI Model Training
The training of AI models involves feeding them large datasets relevant to the task they are designed to perform. For language models, this means massive amounts of text from the internet, books, articles, and other written materials such as Google licencing access to all of Reddit’s text-based data for it’s model training purposes. For video models, it involves training on extensive collections of videos or 3D-generated synthetic data. This process allows the models to learn patterns, structures, and nuances within the data.
Transformer Architecture
At the heart of many modern AI models, including GPT (Generative Pretrained Transformer), LLaMA, and others, lies the transformer architecture. This architecture was introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017 and represents a significant shift in how models process sequences of data.
Transformers are designed to handle sequential data, like text or video frames, in a way that pays attention to the importance of each element in the sequence. The key innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different parts of the input data differently. This is crucial for understanding the context and relationships within the data, whether it’s the relationship between words in a sentence or the sequence of frames in a video. This is the core technology behind OpenAI’s success by mastering the use of the transformer architecture and applying it across data types with ever-increasing compute power OpenAI creates SOTA (State of the art) AI models.
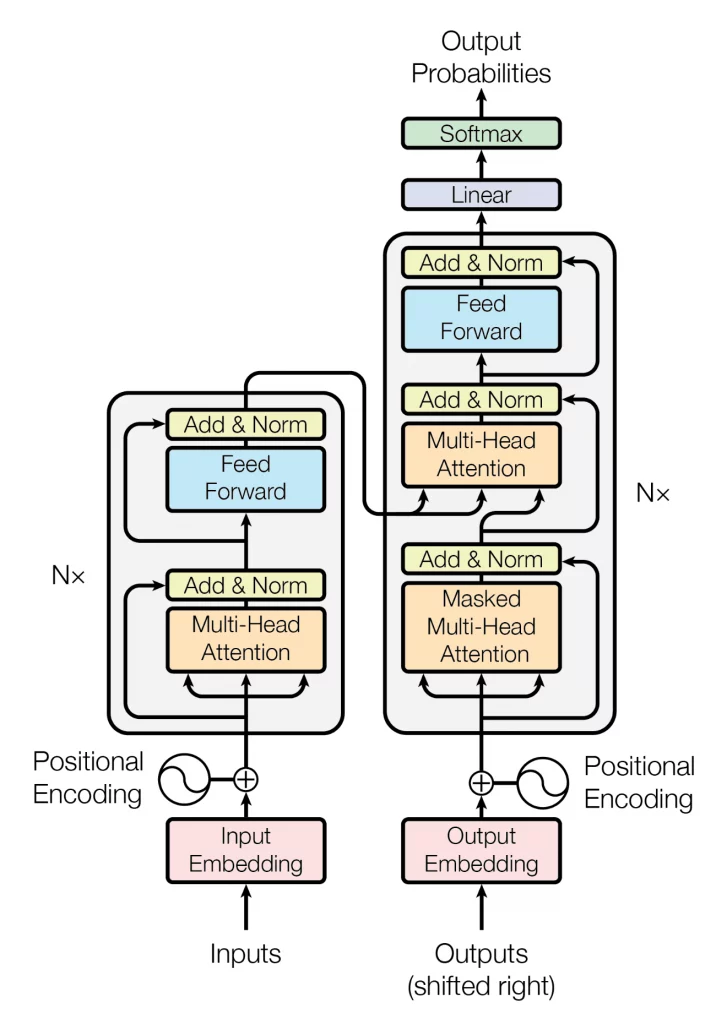
The training process of AI models, especially those based on transformer architectures, typically involves two main phases:
Pretraining: In this phase, the model is trained on a general dataset to learn a wide range of data patterns. For language models, this means learning the structure of language, grammar, and common knowledge from the text. For video models, this means understanding visual patterns, motion, and common objects or actions in videos. It is in this training phase when emergent properties will emerge or so the AI researches will hope.
Fine-tuning: After pretraining, the model can be fine-tuned on a smaller, more specific dataset. This phase adapts the model to perform well on a particular task, such as translating languages, generating human-like text, or recognizing specific actions in videos. This step will be done by the model owner in some cases to introduce properties that the model is lacking in, or if the model is open source such as those available on Hugging Face the community will fine tune a model to improve it overall or in a specific task.
Role of Data
The quality and diversity of the training data significantly impact the model’s performance. Bias in the data can lead to biased predictions, making it crucial to curate and review datasets carefully. By introducing incorrect or corrupt data some un-wanted emergent properties will begin to appear in the model such as a misunderstanding of physics in videos models or incorrect facts in a language model.
Computational Resources
Training these models requires substantial computational resources, often involving powerful GPUs or TPUs. This is because the models need to process and learn from vast amounts of data, and the transformer architecture’s complexity requires significant computational power to handle the self-attention mechanisms efficiently. This is one of the main reasons behind Nvidia’s meteoric rise in share price, as data centres build out the compute capacity to train these models Nvidia is a leader in supplier the GPUs such as their H100 series to train the models. This means that Google, Microsoft, Amazon and smaller data centres and labs are all flocking to buy as many Nvidia GPUs as possible to win the “AI War”.
Emergent Properties
Okay so now we know what these models are, how they are trained and who is doing it, it is time to understand what these emergent properties are and the where they occur. TO keep this blog post relevant I will first look at one of the models every one is excited about right now, OpenAI’s Sora model. This is a video transformer based model, the first that Open AI has released with a research paper and some examples, these videos serve as a great visual example of emergent properties. Lets first take a look at this pirate ship in a cup of coffee.
Prompt: Photorealistic closeup video of two pirate ships battling each other as they sail inside a cup of coffee.
As you can see the video generation capabilities are very impressive, but what is more impressive for this conversation is the way that the model has generated water interaction and physics in a way that looks very realistic and to the naked eye may be indistinguishable to normal water interaction. This is an example of an emergent property. This model was made to generate video. Which when you break it down is just a series of pixels followed by another series of pixels up to the point where yu have 30 or 60 pixels generated for each second of video. So how does a model that is selecting a pixel followed by another pixel understand how physics and fluid dynamics work to the point where it looks believable? Also if this model understand fluid dynamics does that mean we can use the model to carry out fluid experiments? Are scientists jobs going forever?!
Now let’s not get ahead of ourselves, this is where the problem of emergent properties comes, this model doesn’t understand fluid dynamics at all, and if I used a text prompt such as “make me a video of oil moving through a pipe” it would create that video with just as much scientific accuracy as I would, who has had no fluid dynamics education, although it would make it look very pretty and better than I could.
The secret behind this model generating fluid movement without knowing fluid dynamics is that it has seen so many examples of fluid moving in different ways hundreds of thousands of times in the transformer model architecture training process that is has grabbed “attention” to this property and when asked to it has mimicked the property. Therefore, this is an emergent property of a video model, a property it wasn’t explicitly trained for but it has picked it up as there were sufficient examples of it in the training data.
But what happens when there aren’t sufficient examples in the training data or if the training data is incorrect? Well, OpenAI has another example from the Sora model that shows this too:
Prompt: Archeologists discover a generic plastic chair in the desert, excavating and dusting it with great care.
As we can see in this example the model hasn’t gotten physics quite right, instead, the model has misinterpreted how sand interacts with chairs, this is another emergent property, the interaction of objects with sand but it seems like this, right now may be a negative one.
So what could OpenAI do about this? In video models this has quite a nice solution and Nvidia has been working on the issue for a while with its Omniverse suite. This is a system that allows researchers to upload 3D assets which Nvidia will place into environments and apply filters and processing to create a whole load of synthetic data that a model can train on. These are based on game engine models mathematical understanding of physics so they are closer to reality than transformer-based models are. For example, when you run through a puddle in a videogame like Helldivers 2, which looks like a real physical interaction, this is much more real than what OpenAI can produce as the physics in a video game are based on actual mathematics rather than pixel by pixel prediction.
The Omniverse system was first made for teaching robots tasks like traversing a factory using reinforcement learning. Still, there is no reason the same idea can’t be used to input a few hundred videos of objects interacting with sand, using the system to generate thousands more videos of objects interacting with sand using the base 3D models in a whole load of different configurations. Using humans to verify the interaction created looks real then feeding the resulting generated and verified videos into the Sora training data to clean up this emergent property. This is one way of cleaning a negative emergent property or forcing one into a model, synthetic data is a powerful tool in AI that is going to become only more necessary as time goes on the data wells deplete.
So what other emergent properties exist properties exist? One of the most used and talked about uses online for LLMs (Large Language Models) can be classed as an emergent property, that is the fact that LLMs like the GPT-4 model that runs ChatGPT can program across multiple languages and do it quite well. When you take a step back the GPT models and LLaMA models are made to understand language and human text a very human skill. So why then are these models helpful to programmers in this very specific skill? That is because programming is an emergent property of LLMs due to the model that is used to train them.
These models are all trained on open data available on the internet, which includes Stack Overflow code and conversations as well as open Github repositories which hold huge amounts of technical knowledge and code examples, by being trained on all of this data, the models have picked up this programming skill and others such as simple mathematics. Again this model was trained on language so why does it know mathematics? Again this is because there are a lot of examples of simple mathematics and people getting those answers correct on the internet. Whereas for more discrete calculations of complex mathematics, there are fewer examples in the training data so the model may try but will get the complex calculation wrong a lot of the time. This is where fine-tuning comes in, by fine-tuning a model with the kind of calculation and answer a user might look for then the model has a better chance of getting the answer right in the future.
I hope that this blog post has been helpful in understanding more about how AI models work and how emergent properties come into play in the environment. It is good to remember we are at the very early stages of AI architecture and training and there are new ways of training being researched all the time that may eliminate the opportunities and issues discussed here. I am excited to see where emergent properties can go and how those training these huge models will use them in the future. Thank you for reading and feel free to reach out to SeerBI if you would like to discuss AI architecture and its implications!


