Join our Mailing List to hear more!
Join the mailing list to hear updates about the world or data science and exciting projects we are working on in machine learning, net zero and beyond.

Text-to-speech technology has come a long way in recent years, and Microsoft‘s VALL-E (Voice Agnostic Lifelike Language model) is a prime example of this progress. With its ability to generate highly realistic, human-like speech in a variety of languages and accents, VALL-E is setting a new standard for text-to-speech models.
In this blog post, we will dive into the details of VALL-E and explore how it uses techniques such as self-attention and multi-task learning to achieve its impressive performance. We will also discuss the potential applications of VALL-E and its unique design as a language-agnostic model. Whether you are a tech enthusiast or simply interested in the latest developments in text-to-speech technology, this blog post has something for you.
VALL-E is a neural codec language model that is trained using discrete codes derived from an off-the-shelf neural audio codec model, and TTS is treated as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, VALL-E is trained on 60K hours of English speech, which is hundreds of times larger than existing systems. As a result, VALL-E has in-context learning capabilities and can be used to synthesize high-quality, personalized speech using only a 3-second recording of an unseen speaker as an acoustic prompt.
Experiment results show that VALL-E significantly outperforms the current state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. Additionally, VALL-E is able to preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.
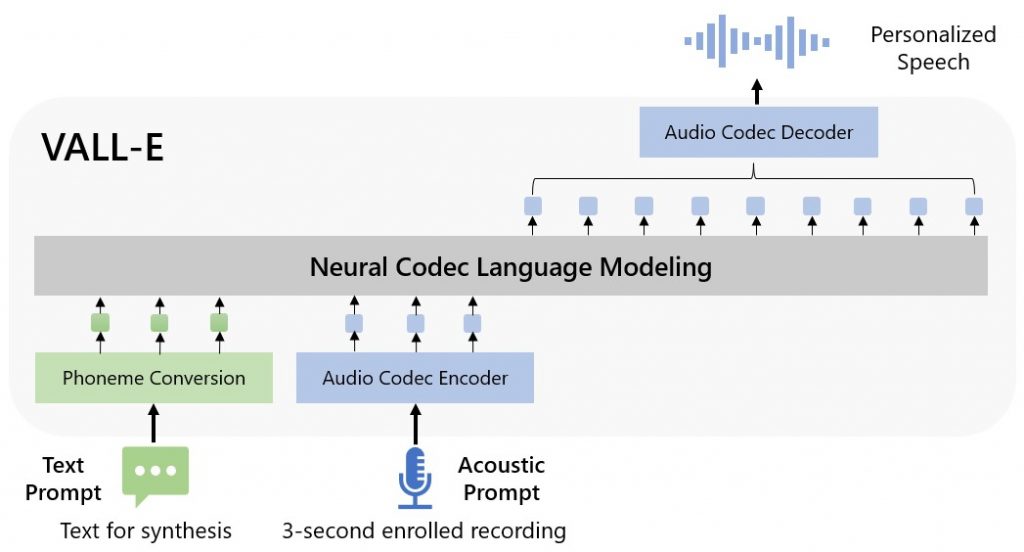
One of the most impressive aspects of Microsoft’s VALL-E model is its ability to generate highly realistic, human-like speech. This model is based on the Transformer architecture, which has proven to be highly effective for a variety of natural language processing tasks.
The Transformer architecture is a type of neural network that has proven to be highly effective for a variety of natural language processing tasks, including language translation, language modeling, and text summarization. It was introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017 and has since become widely used in many state-of-the-art models for natural language processing.
One key advantage of the Transformer architecture is its ability to process long sequences of data without the need for recurrent connections, which can be computationally expensive and difficult to parallelize. Instead, the Transformer uses self-attention mechanisms to allow the model to consider the entire input sequence when processing each element. This enables the model to capture long-range dependencies in the input data and make more accurate predictions.
In addition to its effectiveness and efficiency, the Transformer architecture is also highly modular and can be easily adapted to a wide range of tasks. This makes it a popular choice for natural language processing models like Microsoft’s VALL-E, which uses the Transformer architecture to generate highly realistic, human-like speech.
VALL-E uses self-attention, a technique that allows the model to consider the entire input sequence when processing each element, as well as multi-task learning, which enables the model to learn multiple related tasks simultaneously. These techniques, combined with the model’s large scale and powerful computational resources, enable VALL-E to generate speech that is nearly indistinguishable from a human voice. This makes it a valuable tool for a variety of applications, including speech synthesis and language translation.

One of the most impressive aspects of Microsoft’s VALL-E model is its ability to generate highly realistic, human-like speech. Using the Transformer architecture, which is a type of neural network architecture that is commonly used for natural language processing tasks, VALL-E is able to model the complex dependencies and patterns found in language data.
In addition, VALL-E uses techniques such as self-attention and multi-task learning to further improve its performance. Self-attention allows the model to consider the context of each word in a sentence, rather than just processing the words in a linear fashion.
This allows the model to capture the relationships between words and generate more coherent and natural-sounding speech. Multi-task learning, on the other hand, involves training the model on multiple tasks simultaneously, which can help the model learn more efficiently and improve its performance on each individual task. Together, these techniques enable VALL-E to generate speech that is nearly indistinguishable from a human voice, making it a valuable tool for applications such as speech synthesis and language translation.
Text-to-speech models are valuable for a variety of reasons. They can be used to generate natural-sounding speech from text, which can be useful in a wide range of applications. For example, text-to-speech technology can be used to synthesize speech for digital assistants, such as Apple’s Siri or Amazon’s Alexa, which allows users to interact with these devices using spoken commands.
Text-to-speech models can also be used to read aloud written text, such as articles or books, which can be helpful for people with visual impairments or reading difficulties. Additionally, text-to-speech models can be used to translate written text into spoken language in different languages, which can help facilitate communication between people who speak different languages.
Text-to-speech models can also be useful for educational purposes, such as helping students improve their pronunciation or comprehension of a new language. They can also be used for content creation, such as generating audio versions of written content for podcasts or online videos. Overall, text-to-speech models offer a wide range of potential uses and can be a valuable tool in many different contexts.

In conclusion, Microsoft’s VALL-E (Voice Agnostic Lifelike Language model) is a highly impressive and innovative text-to-speech model that is setting a new standard for realistic and versatile speech generation. Using advanced techniques such as self-attention and multi-task learning, VALL-E is able to generate nearly indistinguishable human-like speech in a variety of languages and accents. Its unique design as a language agnostic model also makes it a powerful and versatile tool that can be used in a wide range of applications and languages. Whether you are a tech enthusiast or simply interested in the latest developments in text-to-speech technology, VALL-E is a model to keep an eye on as it continues to push the boundaries of what is possible with this technology.
If you would like to understand how AI like VALL-E will affect your workplace or how to integrate AI to your organisation or platform for automation or business value speak to one of our data scientists at SeerBI today.
Join the mailing list to hear updates about the world or data science and exciting projects we are working on in machine learning, net zero and beyond.
Fill in the form below and our team will be in touch regarding this service
07928510731
[email protected]
Victoria Road, Victoria House, TS13AP, Middlesbrough


