Create Images You Can Only Dream Of


How Does Stable Diffusion Work?
The technology that can create
The concept is straightforward: use your imagination to create whatever scene, object, or character you wish to see in the image, list it in a description (referred to as a prompt), and within seconds, an array of AI-generated images will appear.
Stable Diffusion was trained on image-caption pairs from LAION-5B, a publicly accessible dataset created from web scraped data called Common Crawl, where 5 billion image-text pairs were divided into separate datasets based on resolution, a predicted likelihood that they would contain a watermark, and a predicted “aesthetic” score (e.g. subjective visual quality).
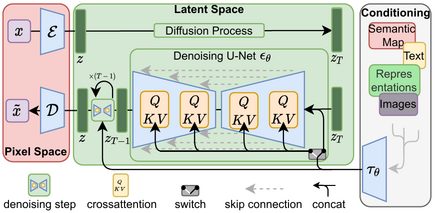
A variation of the diffusion model (DM) known as the latent diffusion model is used by stable diffusion. Diffusion models, which were first used in 2015, are trained with the goal of eradicating repeated applications of Gaussian noise on training images, which can be compared to a series of denoising autoencoders. The variational autoencoder (VAE), U-Net, and an optional text encoder make up the architecture of Stable Diffusion.
Applying Stable Diffusion
How can we use it
Stable Diffusion has multiple use cases for both consumer and buisness applications.
Need a specific image for your blog post but can’t find the right one? Generate it!
Need to see what a banana the size of the empire state building looks like but you don’t know photoshop? Generate it!
Need a specific back drop for your new product launch but you are stuck at home? Generate it!
Need a texture for the game you are creating but can’t get one just right? Generate it!
The applications are endless and the opportunities are ground breaking.

Bespoke Solutions
What you need from inception to Integration
At SeerBI we work with cutting edge machine learning and AI technologies to unlock you organisation’s future and with real applicable use cases.
